
All roads lead to disaster
I can't be the only one thinking this, surely?
At university, I took an ‘introduction to AI’ module. It was good fun, and it introduced me to a lot of ideas that have all become completely irrelevant as of 2020. One such idea was genetic algorithms.
I briefly became obsessed with the idea of evolving artificial life. I’d also recently written a simple 2D physics engine (think Box2D, but less capable), and I liked the idea of combining the two. And so, I implemented a program with some simple rules:
- Every 30 seconds, a random collection of physics bodies - a ‘creature’ joined by ‘muscles’ - spawns into the environment.
- The ‘muscles’ are springs, which extend or shrink either periodically or when one of the physics bodies touches the ground.
- Every 10 minutes, we take the top 5 creatures that attained the greatest x coordinate, and randomly permute them (changing muscle length, muscle activation rules, attachment points, etc.) and use them to create new creatures for the next generation.
Unfortunately, a particularly nasty hard drive failure a few months afterward means that I no longer have the original source code. So, you’ll have to make do with the following MS Paint recreation:
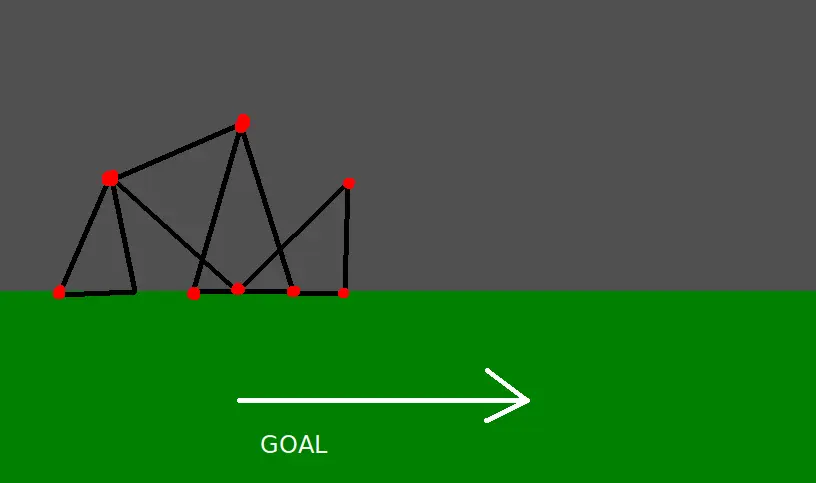
I wanted to see whether, over time, the creatures would slowly learn to wiggle, then crawl, then walk toward their goal.
I set it running and went to the pub.
Unexpected outcomes
When I came back a few hours later, the creatures had learned to fly.
No, I’m not joking: they’d discovered a subtle floating-point precision bug in my physics engine and had exploited it to catapult themselves toward the right side of the screen. Each one was visible on the screen for no more than a few frames before whizzing off into the unknown.
Needless to say, observing this behaviour had a profound and troubling effect on my thinking.
Misbehaviour is a general problem…
I later learned that this behaviour is referred to by AI researchers as ‘misalignment’.
“A system that is optimizing a function […] will often set unconstrained variables to extreme values”
~ Stuart Russell
To economists, it’s known as ‘Goodhart’s Law’.
“When a metric becomes a target, it ceases to be a good metric.”
~ Charles Goodhart
The gist of it is simple: when an ‘agent’ (be it human, artifical, or even just a simple genetic algorithm) applies pressure to a complicated system in service of a goal, most aspects of the system will drift toward whatever extreme state best serves the goal. This happens because complex systems have a high degree of interconnectedness and so almost every aspect of the system has at least some effect on the goal, but the direction of that effect becomes more and more unpredictable as the system grows in complexity. As a result, aspects of the system that appear on the surface to have virtually no relationship with the goal the agent was set end up being manipulated in ways that break our expectations.
Extreme values might be desirable for a single-minded agent with a goal, but they are hardly satisfactory for us people, who depend on a relative degree of stability for survival and prosperity.
In Dan Davies’ ‘The Unaccountability Machine’, Davies makes the case that this sort of misalignment lies at the heart of the majority of the systemic failures we see around us today: climate change, financial crashes, fatal accidents. Leaning on the field of cybernetics, he suggests that some of the more egregious decision-making is not simply a product of malicious intent or individual incompetence, but is instead inherent to complex institutions with insufficient safeguards and a lack of big-picture oversight, leading to narrow goal-chasing that subverts more abstract ethical objectives.
Just as with AI misalignment, the problem is not simply that the policy is ‘evil’, but that the policy insufficiently captures the subtle details of the outcomes we’d actually like to achieve.
…with uniquely harmful potential
So, we’ve established that people, governments, and corporations do this all the time: obeying the letter of a command but not its spirit. What makes super-intelligence different is the lack of safeguards and its vastly superior ability to identify gaps in the rules. If a dirt-simple genetic algorithm discovered a flaw in my code in mere hours, imagine what the AI of tomorrow might be capable of.
In more plain terms: if you tell an AI system to prevent cancer, it might just decide that the simplest course of action is to kill all humans before they have a chance of developing the disease. And, perhaps, all other life forms just to make sure. Even if you tighten your definitions or start preaching Asimov’s laws, the AGI will find ways around it: not because it has any sort of ill intent, but simply because it does not understand human ethics as anything other than narrow rules.
The misalignment problem is real at the smallest scales, and we’ve not yet found a reason to assume that it ceases to be true at larger scales. If anything, evidence seems to point toward misalignment being more of a problem at scale.
This could be nothing
I’m not yet convinced that the current iteration of AI systems are necessarily a precursor to super-intelligence. They still make fairly egregious mistakes that no human would, and there’s increasing evidence that current model architectures are hitting carrying capacities. In my mind, this presents two possibilities:
1) Current models do not possess ‘novel’ intelligence
Rather, they are simply rebottling and reproducing existing sources of human intelligence that are present in their training data.
Note that their ability to react to previously unseen inputs is irrelevant: the point of the training process is to replicate the function that underpins the training data, not simply to regurgitate responses to specific samples in the training data. If that function is ‘intelligence’, then LLMs might simply be performing ‘intelligence mimicry’ without needing to replicate the computation that underpins intelligent reasoning. We already know that even experts have a difficult time telling both apart.
2) The bottlenecks are simply a limitation of current techniques
In this scenario, current models are showing limitations for superficial architectural reasons, and a shift to a new model architecture will continue to push us toward AGI. Intelligence is a learnable skill, and LLM training sets are simply ‘bootstrap’ material for this process.
In other words, the source of intelligence is ‘compute’, not ‘data’, and current AI systems are indeed generalising beyond the patterns already present in their training data.
If I was one to make bets, I’d bet on the first possibility being true. Although their ability to parse and transform outputs is undoubtedly impressive, my limited experiments with today’s models give me reason for pause: when pushed to their limits in novel environments, LLMs start making mistakes that no human would ever make.
However, I can’t deny that the second outcome seems plausible, and it terrifies me. If today’s models continue to make broadly unimpeded progress, we’ll be hitting AGI - and very soon after ASI - in a matter of a decade, perhaps even less. For the first time, humanity will be sharing the planet with something with vastly more reasoning ability than ourselves, and I don’t fancy our chances.
The dice are loaded
You know what? Even if I thought the second possibility was vastly more likely, I’d still bet on the first. In fact, I’d bet everything on the first. Because if current models are on a trajectory toward super-intelligence, it’s game over. I wouldn’t be able to enjoy my winnings because I wouldn’t exist.
We have no workable solution to the alignment problem (and my gut feeling is that a general solution does not exist), and yet we’re busy betting everything on our own demise.
I am an AI pessimist - because I have to be. It’s the only way I can bring myself to get up every morning. The only thing that gives me hope for the future - or hope that there even will be a future - is the idea that this will all suddenly grind to a halt.
The better outcome
What if the threat isn’t existential? What if it’s hot air? What if some insummountable obstacle appears tomorrow and the freight train’s momentum is magically arrested? What if Blade Runner is a feel-good film about humanity’s narrow escape from extinction?
Well, we still have to engage with our new reality. Generative AI is here and isn’t going anywhere. Like digital PFAs, GenAI outputs have polluted our public spaces and poisoned our sense of social trust. We live in a world where anybody can generate passable fake text, images, and video for less than the price of a bottle of tap water, and at a rate vastly outpacing the velocity of legitimate information. Perhaps you believe that you can always separate fact from fiction, but I can guarantee that you’re suffering from survivorship bias.
It might not have reasoning capabilities that rival a human in slow mode, but most of us do not spend our time in slow mode, nor do we require it for our day jobs. Current generation AI still has the capacity to produce mass unemployment, extreme inequality, enable the worst political forces imaginable, and generally act as a force multiplier for the already terrifying economic power of elites. I fear that we’ve only just started to understand the intense and permanent harm that generative AI has wrought on our intellectual commons, and everything that lies downstream of it.
This is suddenly personal to me
Two months ago I found out that I’m going to be a father. I’m in equal parts nervous and elated at the prospect, but I’m not sure how to square those feelings with the prospect that our - their - very survival hangs on a knife edge; and that if they win that particular lottery, they have a life of hardship competing in a world devastated by corporate AI to look forward to.
All things being equal, my child might see the year 2100. Perhaps even 2125 or 2150, if things do not remain equal. And yet, despite my knowledge of the world they are to inhabit, I can scarcely imagine what it will look like in a year, much less a decade or a century.
What now?
I’m not sure what to make about all of this, frankly. I suspect I’m not the only one having similar thoughts though. I was hoping for a conclusion that felt less gloomy, but I’m struggling to find a positive in all of this. I’d love to be convinced that I’m wrong and the future is bright, but I just can’t see it.